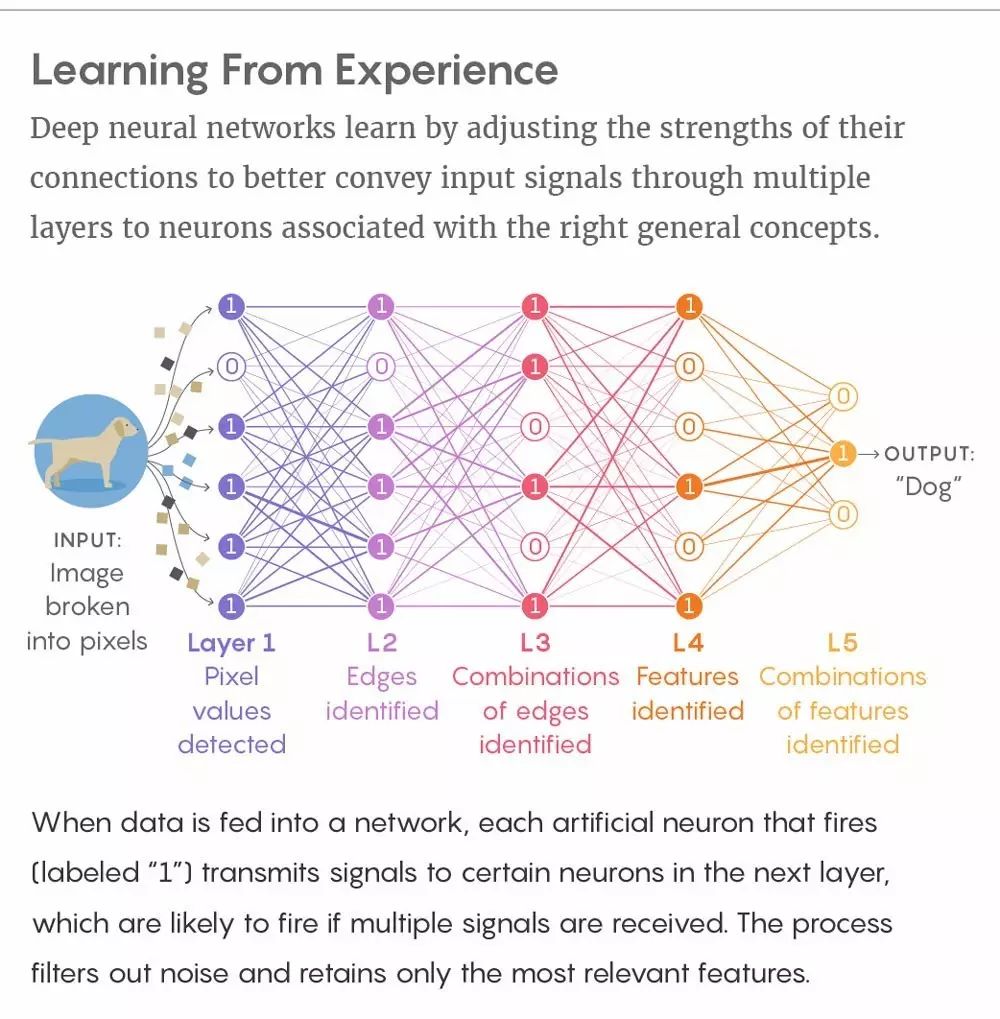
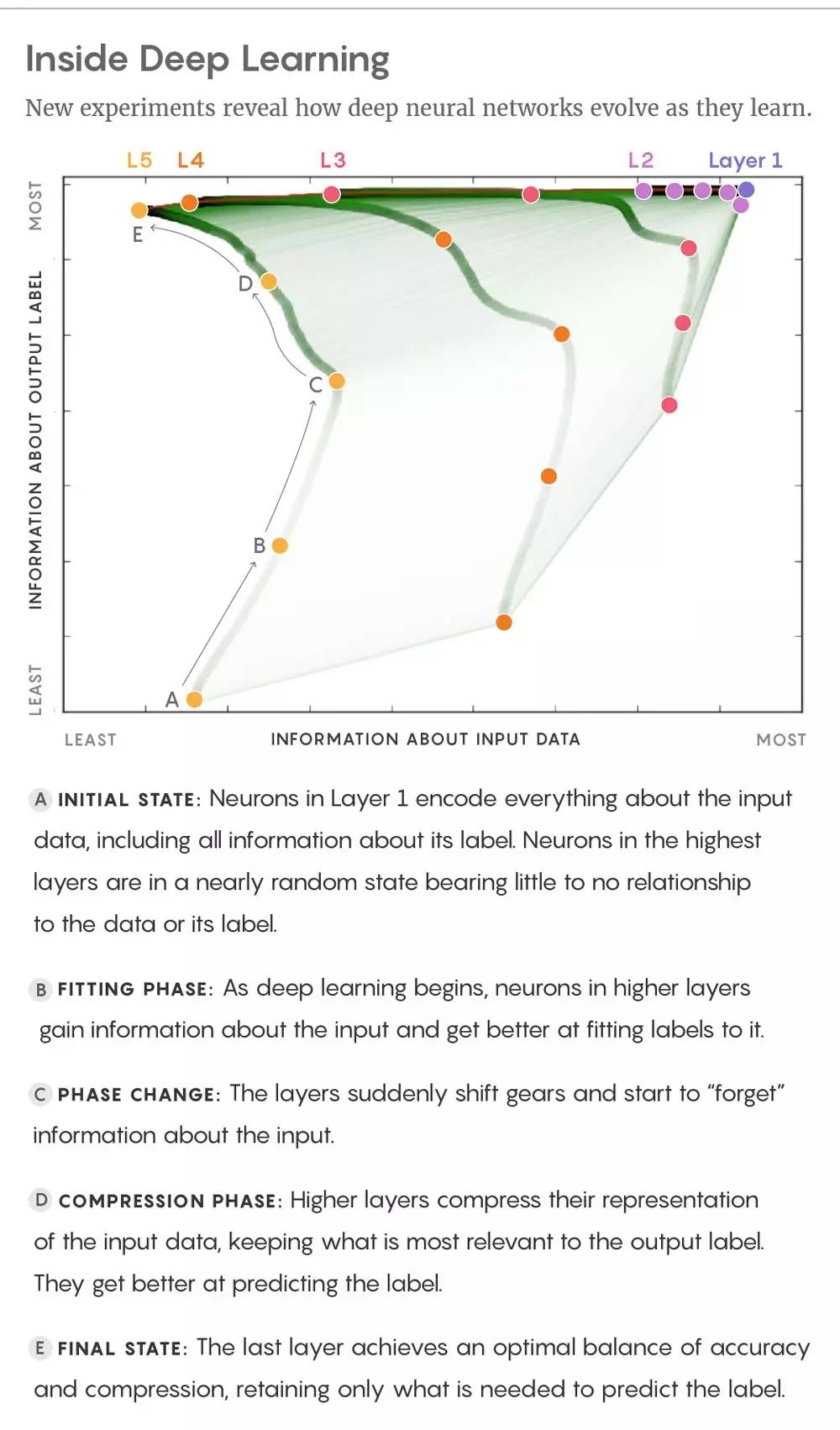
假设 X 是一个复杂的数据集,比如狗的图像像素,Y 是一个被这些数据表征的较简单的变量,比如单词「狗」。通过尽可能地压缩 X 而又不失去预测 Y 的能力,我们在关于 Y 的 X 中可以捕获所有的相关性信息。在 1999 年的论文中,Tishby 与联合作者 Fernando Pereira(现在谷歌)、William Bialek(现在普林斯顿大学)共同将这个概念阐述为一个数学优化问题。这是一个没有潜在黑箱问题的基本思想。
尽管这一隐藏在深度神经网络后面的概念已经讨论了几十年,但是它们在语音识别、图像识别等任务中的表现在 2010 年代才出现较大的发展,这和优化的训练机制、更强大的计算机处理器息息相关。2014 年,Tishby 阅读了物理学家 David Schwab 和 Pankaj Mehta 的论文《An exact mapping between the Variational Renormalization Group and Deep Learning》(变分重整化和深度学习之间的映射关系),认识到他们与信息瓶颈原则的潜在联系。
至于信息瓶颈是不是在所有深度学习中都存在,或者说有没有除了压缩以外的其它泛化方式,还有待近进一步考察。有些 AI 专家评价 Tishby 的想法是近来深度学习的重要理论洞察之一。哈佛大学的 AI 研究员和理论神经学家 Andrew Saxe 提出,大型深度神经网络并不需要冗长的压缩状态进行泛化。取而代之,研究员使用提前停止法(early stopping)以切断训练数据,防止网络对数据编码过多的关联。
Tishby 论证道 Saxe 和其同事分析的神经网络模型不同于标准的深度神经网络架构,但尽管如此,信息瓶颈理论范围比起其它方法更好地定义了这些网络的泛化能力。而在大型神经网络中是否存在信息瓶颈,Tishby 和 Shwartz-Ziv 最近的实验中部分涉及了这个问题,而在他们最初的文章中没有提过。他们在实验中通过包含 60,000 张图片的国家标准与技术局(National Institute of Standards and Technology)(http://yann.lecun.com/exdb/mnist/)的已完善数据集(被视为测量深度学习算法的基准)训练了 330,000 个连接的深度神经网络以识别手写体数字。他们观察到,网络中同样出现了收敛至信息瓶颈理论范围的行为,他们还观察到了深度学习中的两个确切的状态,其转换界限比起小型网络甚至更加锐利而明显。「我完全相信了,这是一个普遍现象。」Tishby 说道。
人类和机器
大脑从我们的感知中筛选信号并将其提升到我们的感知水平,这一奥秘促使 AI 先驱关注深度神经网络,他们希望逆向构造大脑的学习规则。然而,AI 从业者在技术进步中大部分放弃了这条路径,转而追寻与生物合理性几乎不相关的方法来提升性能。但是,由于他们的思考机器取得了很大的成绩,甚至引起「AI 可能威胁人类生存」的恐惧,很多研究者希望这些探索能够提供对学习和智能的洞察。
纽约大学心理学和数据科学助理教授 Brenden Lake 研究人类和机器学习方式的异同,他认为 Tishby 的研究成果是『打开神经网络黑箱的重要一步』,但是他强调大脑展示了一个更大、更黑的黑箱。成年人大脑包含 860 亿神经元之间的数百万亿连接,可能具备很多技巧来提升泛化,超越婴儿时期的基本图像识别和声音识别学习步骤,这些步骤可能在很多方面与深度学习类似。